王洪义,孔梅梅,徐荣青
(南京邮电大学电子与光学工程学院、微电子学院,江苏 南京 210023)
近年来,火灾发生频率越来越高,且火灾的发生往往伴随着一定程度的人员伤亡、环境破坏以及财产损失。为了避免火灾事故带来的危害,应在火焰产生的初期阶段对火焰进行准确快速的检测,这不仅有利于及时控制火情,还可有效降低火灾造成的恶劣影响。
鉴于火焰检测的重要性,人们已对火焰检测方法进行了广泛的研究。目前,有基于人工定义火焰特征和基于卷积神经网络2 种检测方法。基于人工定义火焰特征的检测方法,由于多数火焰目标较小以及阳光、灯光等与火焰颜色相似,因此该方法的检测平均精度低、小目标火焰漏检率高。人们使用将火焰的YUV颜色模型、形状和运动特征相结合的方法[1]和将RGB 颜色模型与ViBe 背景提取算法相结合的方法[2]来提高基于人工定义火焰特征检测方法的效果,但效果仍不理想。卷积神经网络具有较好的自主学习性、容错性以及较快的速度[3],常用于图像的识别和分类。现今,用于火焰检测的卷积神经网络有CNN[4]、Faster RCNN[5]和YOLO[6]系列。其中,YOLO 系列相比于其他卷积神经网络而言,能够较好地提取图像的全局信息,且可以进行端到端的训练,用在火焰检测中更具优势。YOLOV5[7]是目前最新的卷积神经网络,相较于其他YOLO 系列,YOLOV5 具有更快的速度和更高的平均精度。Dai 等[8]使用MobileNet 网络替 换YOLOV3 的 主 干 网 络。赵 媛 媛 等[9]在 原YOLOV3 的基础上增加了第四层检测层。但以上2种改进方法的火焰检测平均精度低、小目标火焰漏检率高,不能满足火焰检测的要求。
为了解决火焰检测平均精度低、小目标漏检率高的问题,本文提出一种改进YOLOV5 的火焰检测算法。使用Transformer Encode[10]模块代替原网络中的部分卷积模块,提升网络提取不同局部特征的能力,提高火焰检测的平均精度。在YOLOV5 的主干网络和检测头中添加CBAM(Convolutional Block Attention Module)[11]注意力模块,提升网络检测小目标的能力,降低火焰检测的小目标漏检率。
1.1 YOLOV5算法简介
YOLOV5 算法由Ultralytics LLC 公司于2020 年5月份提出[7],其图像推理速度比Faster RCNN[12]、YOLOV3[13]和YOLOV4[7]算法都要快,可达到140 帧/s[7]。YOLOV5 分 别 使 用CSPDarknrt53 作 为 主 干 网络、PANet[15]作为颈部和YOLO 检测头[16]作为检测头,其网络结构如图1所示。

图1 YOLOV5网络结构图
1.2 本文算法
本文使用Transformer Encode 模块和CBAM 模块改进原来的YOLOV5网络,不仅提高了火焰检测的平均精度,还降低了小目标火焰的漏检率。改进YOLOV5网络结构如图2所示。

图2 改进YOLOV5网络结构图
1.3 Transformer Encode
Transformer 模块是谷歌公司于2017 年提出的一种简单的神经网络结构,其由Transformer Encode 和Transformer Decode 这2 部分组成[10],最初用于文本的识别。2020 年谷歌公司将Transformer Encode 模块用于图像识别[17]。Transformer Encode 由Embedded Patches、Multi-Head Attention、Add 和Feed Forward这4部分组成,其网络结构如图3所示。

图3 Transformer Encode结构图
在Transformer Encode 模块中,首先将输入的图像进行Embedded Patches,得到一维的向量,然后通过Multi-Head Attention 和Add 得到全局自注意力特征图,最后通过Feed Forward 和Add 获得Transformer Encode的输出。其中,Embedded Patches的作用是对输入的图像进行分割和位置编码[17]。位置编码不仅考虑图像的内容信息,而且考虑不同位置的要素之间的相对距离,有效地关联了物体之间的信息与位置[18]。Multi-Head Attention 的作用是不仅可以注意当前像素点的信息,还可以更好地获取上下文语义信息[19]。Add 的作用是使输入图像从低层直接传播到高层,一定程度上解决了网络退化的问题[20]。Feed Forward的作用是防止模型输出的退化[21]。
Multi-Head Attention 是Transformer Encode的重要组成部分,其结构如图4所示。

图4 Multi-Head Attention 结构图
首先,Transformer Encode 的输入矩阵通过3 个不同权重的变化矩阵得到的查询矩阵Q,键值矩阵K和值矩阵V,然后通过点积注意力,计算自注意力特征图,计算公式如式(1)所示。多个独立的头部可以关注不同的全局和局部信息。多头注意力是通过多组变换矩阵和公式(1)获得多个相互独立的注意力特征图,最后通过拼接得到多头注意力图[22],计算公式如式(2)所示。
其中,dk是矩阵Q、K的列数,softmax 是激活函数,W0、WiQ、WiK、WiV是线性变换时的参数矩阵。
Feed Forward 网络由2 个线性变换函数和1 个ReLU 激活函数构成,Feed Forward 网络操作函数(FFN)的计算公式如下:
其中,W1和W2表示权值矩阵,b1和b2表示偏置项,x表示Feed Forward网络的输入,max表示取最大值[23]。
相比于原YOLOV5 网络中的CSP bottleneck 模块,Transformer Encode 模块能够捕获全局信息和丰富的上下文信息。本文使用Transformer Encode 模块代替原YOLOV5 主干网络末端的CSP bottleneck 模块,增强了卷积神经网络捕获不同局部信息的能力,提高了火焰检测的平均精度。
1.4 CBAM注意力
CBAM(Convolutional Block Attention Module)[24]是一个简单有效的注意力模块,可以集成到任何卷积神经网络中,并且可以与基本网络端到端地进行训练[25]。注意力模块由通道注意力和空间注意力2 个子模块组成,网络结构如图5所示。
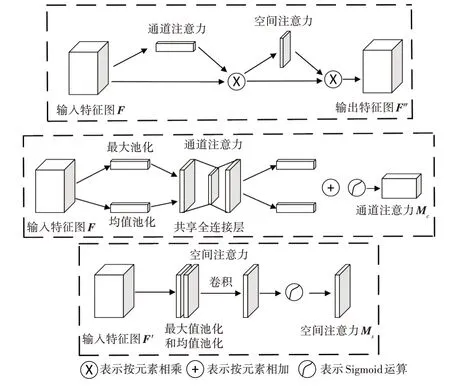
图5 CBAM网络结构图
通道注意力主要关注图像中的目标,而空间注意力则主要关注图像中目标的位置信息[26]。CBAM 模块对于任意给定的特征图输入F∈RC×H×W进行通道注意力运算和空间注意力运算。首先对输入特征图按通道数分别进行最大值池化和均值池化,池化后的2个一维向量共享一个全连接层,将全连接层输出的2个特征图按元素相加,使用Sigmoid 函数进行归一化处理,生成通道注意力图MC∈RC×1×1,再将MC与输入特征图按元素相乘,获得通道注意力调整后的特征图F′[27]。其次将F′按空间进行最大值池化和均值池化,将2 个池化生成的二维向量拼接后进行卷积操作[27],从而生成空间注意力图MS∈R1×H×W,再将MS与F′按元素相乘得到CBAM 的最终输出特征图F″。CBAM总体运算过程可描述为:
其中 表示按元素相乘。
CBAM 模块不仅能够关注图像中的目标,还能够关注图像中目标的位置。在原YOLOV5 网络中增加CBAM 注意力模块,能够增强网络提取图像特征的能力,对于小目标火焰能够较好地提取特征,可降低小目标火焰的漏检率。
2.1 实验环境
本文实验基于Win10操作系统,显卡为1块16 GB NVIDIA Tesla P100,内存为125 GB。采用PyTorch深度学习框架和Python语言搭建YOLOV5网络模型。
2.2 实验数据集
本文的实验数据集包括公开数据集BoWFire、Bilkent 大学公开火焰视频库和互联网下载的火焰图片,涵盖室内、森林、城市建筑和工厂等多种场景,共3038 幅。实验中的训练集、验证集、测试集和小目标火焰测试集划分如表1所示。
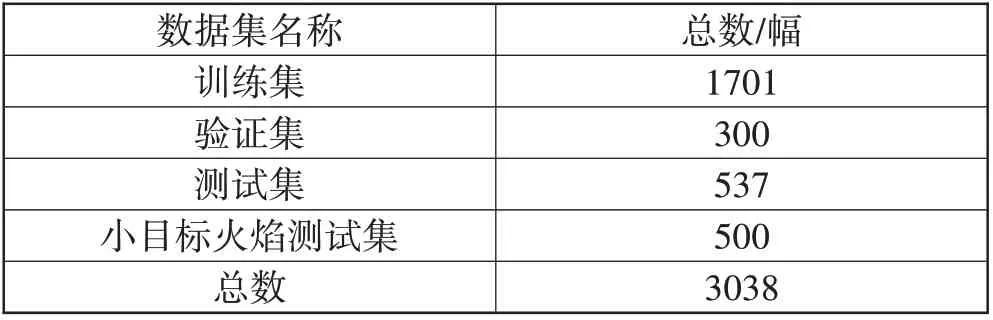
表1 实验数据集
2.3 实验结果分析
本文评估指标采用平均精度(AP)、每秒钟检测图片张数(FPS)和小目标漏检率等较为常见的评价指标来评估本文算法的性能,其中平均精度计算公式为[28]:
式(6)中,TP 为火焰目标被正确检测的图像数量;
FP 为非火焰目标被检测为火焰的图像数量;
FN为火焰目标被漏检的图像数量。
2.3.1 AP和FPS分析
本次实验使用改进YOLOV5火焰检测算法,分别与目前使用较多的Faster RCNN、YOLOV3、YOLOV4和YOLOV5 等火焰检测算法在同一测试集上进行实验,实验结果如表2所示。

表2 火焰检测结果
由表2 分析可知,使用CBAM 注意力和Transform Encode 进行改进的YOLOV5算法相比于原YOLOV5、YOLOV4、YOLOV3 和Faster RCNN 等火焰检测算法,平均精度分别提升了2.4 个百分点、2.2 个百分点、8.1个百分点和22.4 个百分点。改进后的YOLOV5 算法FPS 仍高于YOLOV4、YOLOV3 和Faster RCNN 等火焰检测算法,达到34 帧/s,能够满足火焰检测的实时性要求。火焰检测部分结果如图6所示。

图6 改进YOLOV5算法检测结果
2.3.2 小目标漏检率分析
为了进一步验证基于改进YOLOV5 算法的火焰识别的有效性,本文使用以上5 种算法在500 幅小目标火焰图像上进行实验,实验结果如表3所示。

表3 小目标火焰检测结果
由表3 分析可知,使用CBAM 注意力和Transform Encode 进行改进的YOLOV5 算法相比于原YOLOV5、YOLOV4、YOLOV3 和Faster RCNN 等火焰检测算法,小目标漏检率分别降低了4.1个百分点、2.7个百分点、5.5个百分点和0.4个百分点。小目标火焰部分实验结果如图7所示。从图7中可以看出改进后的YOLOV5算法对小目标火焰有较好的检测能力。

图7 小目标火焰检测结果
2.4 消融实验
本文通过构建消融实验来逐步探索CBAM 注意力和Transform Encode 对原YOLOV5 算法的影响。使用数据集中的测试集和小目标火焰测试集作为本次实验的图像数据,实验结果如表4所示。

表4 消融实验结果
由表4 分析可知,CBAM 注意力和Transform Encode 对原YOLOV5 网络的检测能力有较大的提升。CBAM 注意力使原网络的小目标漏检率降低了3.9 个百分点,增强了原网络对小目标的检测能力。Transform Encode 使原网络的平均精度提升了1.7 个百分点,提升了原网络提取图像特征的能力。
实验结果表明,本文改进的YOLOV5火焰检测算法能够对各种场景下的火焰目标和小目标火焰进行有效的检测,具有检测平均精度高、漏检率低等优点。
本文使用Transform Encode 模块和CBAM 注意力模块改进YOLOV5火焰检测算法,增加了网络捕获不同局部信息和提取图像特征的能力。相比于原YOLOV5、YOLOV4、YOLOV3 和Faster RCNN 等火焰检测算法,改进后的YOLOV5算法具有较高的火焰检测精度,其精度可达83.9%,同时具有较低的小目标火焰漏检率,仅为1.6%。另外,FPS可达34帧/s,满足火焰检测的实时性要求。
猜你喜欢火焰注意力卷积最亮的火焰音乐天地(音乐创作版)(2022年1期)2022-04-26让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02缤纷的火焰学苑创造·A版(2021年2期)2021-03-11从滤波器理解卷积电子制作(2019年11期)2019-07-04漂在水上的火焰动漫星空(兴趣百科)(2019年5期)2019-05-11基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13吹不灭的火焰学与玩(2017年6期)2017-02-16A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21