李坤奇,孟润泉,李凤莲
(太原理工大学 a.电气与动力工程学院,b.信息与计算机学院,太原 030024)
在碳中和与新能源占比不断提升的背景下,发电侧和用电侧的峰谷差逐年增大[1],居民用电短期负荷预测问题有着较高的研究价值。高效准确的负荷预测有助于电力系统调度工作的稳定性和经济性[2],提升用电效率,减少能源浪费。在对居民用电负荷进行预测时,传统方法是基于居民区整体的负荷数据进行预测[3]。但随着智能电表的普及,用户用电行为的数据精度更高、粒度更细、特征更多。基于用户层面的深度数据挖掘可以使预测模型学习到更多规律,有助于进一步提升负荷预测精度[4]。
对用户进行聚类分析有助于提升负荷预测精度。如文献[4-5]在建立预测模型前,根据用户的用电行为特性,采用K-means聚类算法对用户进行聚类分析,验证了聚类分析在负荷预测任务中的可行性和有效性,有助于负荷预测模型学习到不同用户群的用电趋势信息。已有方法通常是对用电数据采用聚类分析得到用户群信息后,针对每个用户群分别建立预测模型,导致预测模型数量偏多,且各模型只能学习到相应用户群的用电信息,无法学习到其他用户群的用电信息,因此也无法获取不同用户群用电规律之间的潜在联系。另外,K-means[6]以及层次聚类算法等为常用的时间序列聚类算法。K-means算法简洁高效,但算法性能易受初始聚类中心的影响。BIRCH算法属于层次聚类算法,其性能不受初始聚类中心影响,通过生成一棵具有层次结构的聚类特征树,聚类结果有更好的可解释性,且性能更优,灵活性更强[7]。因此,为克服已有方法缺陷,本文提出了一种基于BIRCH(balanced iterative reducing and clustering using hierarchies)聚类算法融合单预测模型的居民用电短期负荷预测方法,首先采用BIRCH聚类算法进行用户用电量的聚类分析,以得到多个具有不同用电习惯的用户群,挖掘不同用户群的用电规律之间的潜在联系,构建可更精确反映用户用电特性的多特征时间序列用电数据,为后续预测模型构建提供更优质的特征属性数据,并有助于降低预测模型数量。
在居民用电负荷预测模型构建方面,目前用于短期负荷预测的方法主要包括指数平滑法[8]和多元线性回归[9]等统计方法,以及分类和回归(classification and regression tree,CART)决策树、支持向量机(support vector machine,SVM)[10]、人工神经网络(artificial neural network,ANN)和深度学习等机器学习方法。统计方法采用传统的统计学思想,预测模型有较好的解释性,但模型较为简洁,在数据量较大的情况下无法充分利用数据中的非线性信息[11]。CART决策树算法采用自顶向下递归结构建树,较适合高维数据,但模型性能易偏向多值属性数据,且忽略了属性之间的相关性。SVM能较好地处理非线性问题,且泛化性能较好,但存在对大规模训练样本较难实施缺陷。人工神经网络及基于神经网络的各种深度学习模型,在非线性数据量较大的情况下,性能更优,近年来在负荷预测领域应用广泛。
作为深度学习常用结构,CNN(convolutional neural network)是包含卷积计算的神经网络,可高效实现输入特征的提取,被广泛应用于图像识别、语音识别及居民用电量负荷预测等领域[12]。在居民用电预测领域,CNN在提取高维特征和压缩时间窗上有较好效果。如文献[13]在构建负荷预测模型之前,采用CNN网络预先对输入数据进行处理,取得了较高的预测精度。另一种常用结构是RNN(recurrent neural network),由于RNN在网络中引入了循环结构,因此能更好地学习动态时间序列数据的时序特性,预测精度更高[14]。GRU(gated recurrent unit)[15]和LSTM(long-short term memory)[16]是RNN的两种改进模型,由于添加了门结构,从而能更有效地挖掘时间序列包含的潜在规律。如文献[17]将LSTM应用于单个居民用户的短期负荷预测,取得了较高的预测精度。
针对上述研究现状,本文提出了一种BIRCH聚类算法融合CNN-GRU预测模型的居民用电短期负荷预测方法(简写为BIRCH-CNN-GRU).所提出方法,首先基于BIRCH聚类算法对用户用电数据进行聚类分析,以构建包含用户群负荷数据的多特征时间序列数据集,接着进行CNN-GRU预测模型训练,最后,基于居民用电公共数据集进行预测性能分析,验证了本文方法的有效性。
1.1 居民用电短期负荷预测方法设计思路

(1)
图1给出了本文提出的一种新型的居民用电短期负荷预测方法设计框架。

(2)
聚合后的负荷信息可以由式(3)表示:
(3)
基于聚合结果,将多个用户群的负荷数据、融合时间以及气候等特征信息,得到多特征时间序列数据集,用于后续预测模型训练及性能测试。
相比于传统方法,本方法的优势在于:由于输入数据中不仅有总负荷曲线,也有不同用户群的负荷曲线。预测模型不仅可以学习到不同用户群的用电规律,而且可以学习到不同用户群用电趋势之间的潜在联系,因此预测精度更高,拟合速度较快,使得训练模型的时效性更高。

图1 BIRCH-CNN-GRU预测方法Fig.1 Methodology of BIRCH-CNN-GRU forecasting method
1.2 多特征时间序列数据集构建
除了历史负荷数据外,居民用户的用电行为与时间因素、气候因素也有较强相关性[8]。季节、时刻、节假日等因素会显著影响居民的用电行为,因此本方法采用月、日、星期、时刻、以及是否为节假日等5个时间变量。气候因素的变化会影响居民用电需求。本方法选取与用电负荷相关性较高的平均温度、平均湿度等两个气候变量。
综上所述,本方法构建了包含时间变量、气候变量以及负荷变量3种特征的居民用电数据集,具体如表1所示。

表1 多特征时间序列用电数据集结构Table 1 Multivariate time series dataset
本文提出的BIRCH-CNN-GRU负荷预测方法融合了BIRCH聚类算法,以及CNN-GRU预测模型。其中BIRCH聚类算法用于对居民用电量进行聚类分析,对聚类分析后的用户群用电量进一步融合时间以及气候信息以得到居民用户群用电数据特征,将用户群用电特征数据划分为训练集、验证集及测试集,其中训练集用于构建CNN-GRU预测模型,验证集用于对模型性能进行验证及优化,并用测试集对模型性能进行评估。
2.1 基于BIRCH聚类算法的居民用电多用户群构建

为了提高预测性能,本文采用BIRCH聚类算法结合最优轮廓系数准则寻优得到最佳居民用电用户群数量。寻优时,将居民用电用户群数量设置为一个动态寻优范围,此处设置为[2,10],则BIRCH聚类算法分别运行9次,得到9组聚类结果,其中的最优轮廓系数对应的聚类数即为最佳居民用电用户群数量。
聚类分析的具体步骤如下所示:

2) 归一化。对平均日负荷用电量进行归一化,以准确提取用户的日内用电趋势,避免不同用户的用电总量差异对聚类结果产生影响。归一化公式如式(4)所示。
(4)
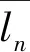
3) 根据实际情况,设定聚类数目k的参数空间。对每一个聚类数目k,采用BIRCH聚类算法对数据集进行聚类分析,得出每一个聚类数目对应的聚类结果。
其中,BIRCH聚类算法特征树的每个节点由包含3个元素的聚类特征(cluster feature,CF)表示,如式(5)所示。
(5)
式中:Nnodes为簇内样本点的数量,对应本文为同一用户群用户数量。xn为样本点的表征向量,对应本文为用户n归一化后的平均日负荷用电量。LS为簇内所有点的代数和,SS为簇内所有点的平方和。
4) 求各聚类结果的轮廓系数。轮廓系数S用于衡量聚类的效果,以确定最优聚类数。轮廓系数的计算方式如式(6)所示。
(6)
式中:Nnodes为样本点的总数;
a(i)用于量化簇内的凝聚度,即样本i到簇内各样本点距离的均值;
b(i)用于量化簇间分离度,即样本i到其他簇样本点距离的均值。Ninside为样本pi所在簇的样本点个数,pj为样本pi所在簇的其他样本点;
Noutside为样本pi所在簇外的样本个数,qj为样本pi所在簇外的样本点。
5) 采用最大轮廓系数对应的聚类数目k和聚类结果作为最优类簇数M和最终聚类结果,每个用户归属于一个用户群。轮廓系数越大,聚类效果越好,以本文实际应用为例,更大的轮廓系数代表用户群内用户的用电习惯更加相似,不同用户群的用户用电习惯更加不同。
6) 每个用户群内,用户的历史负荷数据相加,汇总得到每个用户群的历史负荷用电量。
2.2 居民用电短期负荷CNN-GRU预测模型构建
为了对多特征时间序列用户群数据进行充分学习,本文进一步提出了CNN-GRU居民用电量预测模型。模型结构主要包括CNN层、GRU层和全连接层,整体网络结构如图2所示。
模型中每层描述如下:

图2 CNN-GRU网络结构Fig.2 CNN-GRU architecture
1) CNN层。本模型的CNN层包含一个卷积层和一个池化层。卷积层用于挖掘各用户群负荷数据与气候和时间等变量之间的潜在关系,并提取高维特征。以M表示用户群数量,则表征居民用电信息的输入数据包含(8+M)个时间序列,每个时间序列包含48个时刻的历史数据,因此单个输入样本为(8+M)×48的矩阵。卷积层通过U个卷积核,将居民用电信息映射为U个时间序列,输出U×48的矩阵至池化层。之后池化层通过最大值池化将居民用电信息映射为U×24的矩阵,从而在保留有效信息的同时,压缩时间序列的长度,减少后续GRU网络的训练时间。
2) GRU层。本模型搭建了双层GRU结构,以充分学习居民用电负荷数据的时序特性。基于CNN层输出的U×24的用电信息矩阵,由第一层GRU提取时序特性,并传递相同格式的用电信息矩阵至第二层GRU,第二层GRU再进一步提取时序信息后,由最后一步神经元输出U×1格式的表征居民用电信息的向量至全连接层。
GRU单元的基本结构如图3所示,数学描述如式(7)所示。在图3中,箭头所指方向为数据流动方向。
(7)
图3和式(7)中,×为矩阵的数乘,σ为激活函数Sigmoid函数,tanh为激活函数,“1-”表示该链路向前传播的数据为1-zt.zt和rt为更新门和重置门的输出,xt为输入,ht-1为上一隐藏层的输出,ht为隐藏层的输出。

图3 GRU网络基本单元Fig.3 GRU basic unit structure
3) 全连接层。包含V个神经元的全连接层对GRU网络提取的居民用电信息做进一步非线性映射,最后由包含单个神经元的输出层输出负荷预测结果。全连接层及输出层的计算公式如式(8)所示。
y=W1×V·σ(WV×U·hU×1+bV×1)+b1×1.
(8)
式中:y为居民用电负荷预测值,hU×1为GRU网络输出的表征居民用电信息的向量,WV×U和bV×1为全连接层的权重矩阵和偏置向量,W1×V和b1×1为输出层的权重矩阵和偏置。
为验证所提负荷预测方法的可行性与精确性,本文选取爱尔兰能源管理委员会(commission for energy regulation,CER)发布的公开数据集进行实例验证[18],选取了数据集中3 639户居民,自2009年8月1日至2010年12月31日,共17个月的数据。数据集被划分为训练集、验证集和测试集。其中训练集为2009年8月1日至2010年7月31日负荷数据,共365 天的数据,随机取80%得到,剩余20%数据作为验证集;
测试集为2010年8月1日至2010年12月31日共153天的负荷数据。负荷数据采样粒度为30 min.
本文使用训练集对BIRCH-CNN-GRU 预测方法所用模型进行训练,建立居民用电短期负荷预测模型,采用测试集对构建的模型性能进行测试及评价。每个输入样本的时间窗长度为24 h,相应的输出样本为1 h后的总负荷值。
同时,将预测结果与相同条件下ANN、CNN、CNN-GRU在训练时间与预测精度维度等方面进行比较,以验证模型效果。其中ANN模型由3层全连接层构成,CNN模型由3层CNN单元和2层全连接层构成,CNN-GRU模型采用2.2节所提出的思路搭建,其中卷积层卷积核数U、GRU每层神经元数W、全连接层神经元数V分别设置为128、32、32.
3.1 实验环境配置
本文实验环境采用Intel i5-8265U处理器,Intel UHD Graphics 620显卡。采用Python3.6作为编程语言,深度学习架构基于Tensorflow框架以及Scikit-learn机器学习库,绘图工具采用Matplotlib绘图库。
3.2 实验评价指标
为了评估所提出方法的预测性能,以平均绝对百分比误差MAPE、均方根误差RMSE为评价指标。计算方法如式(9)-(10)所示。
(9)
(10)
式中:n为测试样本个数;
Xact(i)和Xpred(i)分别为第i时刻的用电负荷电量真实值和预测值。
3.3 用户群聚类分析
对3 639户居民的平均日负荷用电量进行BIRCH聚类分析,当聚类数增大时,轮廓系数的变化趋势如图4所示。当聚类类别数为2和3时轮廓系数较大,即聚类效果较好。为保留更多的用户用电信息,我们设定聚类类别数为3,并根据聚类结果将3 639户居民数据划分为3类,得到3个用户群的用户数分别为1 163、2 274、202个。各用户群的平均负荷曲线如图5所示。可以看出,不同用户群的用电模式有明显区别。

图4 不同聚类类别数的轮廓系数结果Fig.4 Silhouette scores of different cluster number
3.4 预测结果分析
表2为各模型在2010年8月到12月连续5个月的日负荷预测结果。本文所提方法的MAPE和RMSE分别为2.932 1%和78.973 9 kWh.通过比较本文提出的BIRCH-CNN-GRU方法与ANN模型、CNN模型、CNN-GRU模型的预测结果,可知本文所提方法在2项精度指标上都有明显优势,MAPE平均值分别降低了24.33%,18.01%,16.74%,RMSE分别降低了20.53%,12.43%,16.73%.

图5 2010年9月1日至3日各用户群平均负荷曲线Fig.5 Average load curve of each user-group from September 1 to 3, 2010
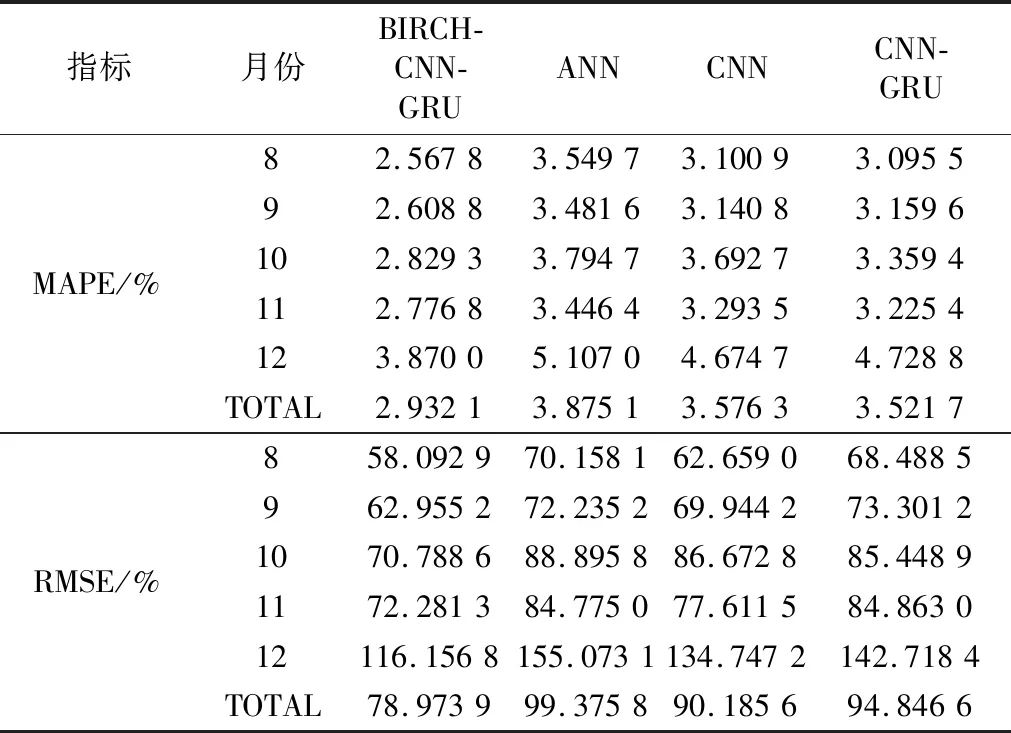
表2 负荷预测结果对比Table 2 Prediction performance comparison over test data
为了更直观显示本文所提出模型及对照组模型的预测效果,以2010年9月1日为例绘制实际负荷曲线及预测负荷曲线的对比图如图6所示。可以看出,与其他几种对比模型相比,本文方法预测负荷曲线与实际负荷曲线更接近。

图6 2010年9月1日预测结果Fig.6 Prediction results on September 1, 2010
此外,绘制前150个时期(Epoch)的训练过程中的误差下降曲线,纵轴为RMSE,横轴为时期,如图7所示。可以看出,相比于其他3种方法,BIRCH-CNN-GRU方法的收敛速度更快,即子用户群的用电趋势信息有助于提升模型拟合速度。
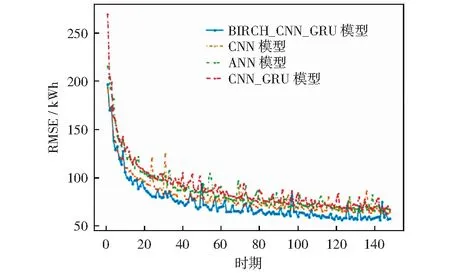
图7 模型训练过程中的误差变化趋势分析Fig.7 Error variation trend analysis during model training
本文提出了一种BIRCH聚类算法融合CNN-GRU预测模型的居民用电短期负荷预测方法。所提出方法可以更充分地利用智能电表提供的历史负荷数据,有更高的预测精度。基于实际数据集的算例显示,本方法相比于ANN、CNN、CNN-GRU等方法,在预测精度层面有明显优势。未来主要从以下两个方向展开研究为:
1) 本文只考虑了单点预测和单步预测。但是在自动化调度过程中,概率预测和多步预测可以为自动化调度策略提供更多的依据。因此未来的工作将探索基于本方法的概率预测和多步预测。
2) 本方法目前只考虑了用户的负荷特征,没有考虑用户的其他特征。由于智能电表收集的信息越来越多样化,下一步将研究更多的用户信息加入到特征集中,并对预测模型性能进行进一步改进优化,以进一步提升负荷预测精度。
猜你喜欢用户群用电聚类基于协同过滤和Embedding的冷启动推荐算法研究消费电子(2021年6期)2021-07-17用煤用电用气保障工作的通知中国化肥信息(2021年12期)2021-04-19安全用电知识多中学生数理化·中考版(2020年12期)2021-01-18从资源出发的面向用户群的高校图书馆资源推荐模型分析求知导刊(2019年17期)2019-10-18基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08为生活用电加“保险”中学生数理化·中考版(2018年12期)2019-01-31用电安全要注意小学生必读(中年级版)(2018年10期)2019-01-04基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26一种层次初始的聚类个数自适应的聚类方法研究电子设计工程(2015年6期)2015-02-27公共图书馆的用户群和服务人员的分析黑龙江史志(2014年12期)2014-11-24