刘 扬,杜帅兵
(1.华北水利水电大学 黄河流域水资源高效利用省部共建协同创新中心,河南 郑州 450046;
2.华北水利水电大学 信息工程学院,河南 郑州 450046)
水是生命之源,也是社会经济发展的基础。准确有效地预测区域用水量,对分析区域水资源平衡、制定合理有效的水资源调配方案及促进社会经济协调发展具有重要意义[1]。受环境变化和人类活动的耦合影响,区域用水量信号呈不确定性、非平稳状态[2]。目前对于用水量预测的研究十分广泛,但如何使模型更加高效、预测更加精准是需要解决的问题之一。
目前,用水量预测的方法主要分为传统预测法(回归分析法、用水定额法、灰色模型法、系统动力学模型法等[3-5])与新型预测法(神经网络法、机器学习法、混合算法等[6-7])。用水定额法对于定额数具有强依赖性,并且受限于当时的社会、经济等因素;
回归分析法选用不同的影响因子时,其结果偏差较大[8];
灰色模型法受信号的突变点影响较大[9];
神经网络法收敛速度慢和易陷入局部最优解的情况有待进一步改进。
单一模型所表现出的非线性特征往往有限,存在精度低、稳定性差等问题,而混合模型的预测精确度和稳定性相较于单一模型而言表现更优[10]。例如:刘志壮等[11]使用基于小波分解随机森林和自回归模型(ARMA)的小波-随机森林-ARMA 组合模型预测短期的用水量,结果表明,结合小波分解的组合模型预测精度明显提高,能够应用于供水调度。李彦彬等[12]采用HP 滤波对郑州市用水量进行分解,结合GMLSSVR 模型对用水量进行预测,HP-GM-LSSVR 预测模型大大提高了预测精度。然而小波分解的结果依赖于事先选取的小波基函数和分解层次,在解决实际问题时小波基和分解层次往往难以确定[13];
而HP 滤波器依赖于调节参数,在具体应用中存在一定局限性[14]。
不同于小波分解,经验模态分解的方法仅依赖于信号的自有特性,不需要提前选定基函数,这与小波分解有本质性的区别。通过经验模态分解后得到的各个分量较为平稳且有规律性,可以反映原始信号的内在特征,因此广泛应用于信号处理中。闫国辉等[15]将经验模态分解(Empirical Mode Decomposition,EMD)与小波降噪(WDD)进行结合构建了EMD-WDD 模式分解方法并用于径流预测,结果表明基于EMD-WDD 的模式分解预测精度比只用EMD 分解的预测精度高。赵国羊等[16]基于模态分解构建人工神经网络(ANN)和支持向量回归机(EMD-SVR)耦合干旱模型,提高了预测的精度,结果表明基于EMD-ANN 和EMDSVR 模型的预测精度明显提高。
通常,对位于序列端点处的值难以确定其是否为序列的极值点,若直接将端点处的值视为极值点,则在对极值序列上下包络和求均值时会产生一定的误差,且误差会传入序列内部,导致EMD 的端点效应影响到整个分解过程。基于此,本文构建出一种基于改进EMD 结合麻雀搜索算法(Sparrow Search Algorithm,SSA)优化核极限学习机(Kernel Based Extreme Learning Machine,KELM)的EMD-SSA-KELM 混合用水量预测模型。首先通过LSTM 对原始用水量信号两端的极值进行延拓,找出序列两端的极值点与原始序列合并再进行经验模态分解,得到一组用水量本征模态函数(Intrinsic Mode Function,IMF)分量和一个残差序列;
然后分别输入至SSAKELM 用水量预测模型中;
最后将预测的分量与残差序列合并得到最终的用水量预测结果。
1.1 经验模态分解
经验模态分解[17]对信号处理后,得到的分量状态较为平稳、规律性较强,能反映序列的内在特征,是一种非常灵活的信号处理方法,其基本实现步骤如下。
(1)记原始用水量信号为x(t),分别求出极大值和极小值。
(2)采用3 次样条插值法,对用水量序列的极大值和极小值两组序列分别进行拟合。记极值点序列拟合的上、下包络线分别为fmax(t)、fmin(t),将其均值记为m1(t),x(t)与m1(t)的差记为h1(t),均值m1(t)的计算公式为
本征模态函数需满足以下两个约束条件:①记某个本征模态函数为hk(t),则hk(t)的极值点和零点个数最多相差1 个;
②极大值、极小值序列对应拟合的上、下包络线的均值为0。在分解中判断h1(t)是否满足上述两条约束条件,若满足则执行步骤(3),若不满足则将h1(t)作为新的x(t)执行步骤(1)和(2)。
(3)记第一个满足本征模态函数要求的分量hk(t)为IMF0,将原始序列x(t)与IMF0 相减的序列记为r1(t),将其作为新的原始序列,重复步骤(1)和(2),当余量函数rn(t)单调时即可停止分解,将其作为残差序列。其表达式如下:
根据分解算法,原始信号x(t)与n个IMF 分量和残差分量之和相等,其表达式为
式中:rn(t)为残差分量;
hj(t)为第j个IMF 分量[18-21]。
1.2 核极限学习机
极限学习机是一种改进的单层反向传播神经网络,由Huang[22]等于2004 年提出,它通过求解隐含层输出矩阵加号广义逆的方式代替反向传播神经网络中迭代更新权重的算法,得到隐含层和输出层权重的速度大大提高。为了使极限学习机的泛化能力更强,避免在隐含层随机分配权重,引入核参数来代替随机产生的隐含层参数,构成核极限学习机。任意给定n个输入样本{(xj,tj)}(j=1,2,…,n),则含有m个隐含层神经元的网络输出tj表达式为
式中:β为隐含层和输出层之间的连接权重;
g(x)为激活函数;
xj为第j个输入向量;
wi、bi分别为输入层和隐含层之间第i个神经元的权重、偏置。
将式(4)描述为矩阵方程表示如下:
式中:H为隐含层的输出矩阵;
T为期望输出矩阵。
由广义逆理论可得:
式中:H+为矩阵H的加号广义逆。
然而,随着训练样本量的持续增长,样本可能会出现复共线性的问题,即在计算H+=HT(HHT)-1的过程中,HHT矩阵可能会出现奇异,导致无法求解的问题。根据岭回归理论,在HHT的主对角线上加上正则化参数C,可避免HHT矩阵奇异、特征根为0 的问题,此时输出权值的求解表达式为
式中:I为单位对角矩阵;
C为正则化参数。
使用核函数ΩELM=HHT,即用ΩELM=h(xi)·h(xj)=K(xi,xj)来代替矩阵HHT的计算,其中h(xi)=H为隐藏层的输出,K(xi,xj)为核函数,xi、xj为不同的输入向量,则输出函数的表达示为
式中:ΩELM为核函数。
核函数的种类有很多,如线性核函数、多项式核函数等,本文选用参数较少、通用性强的高斯核函数:
式中:γ为高斯核函数的参数。
1.3 麻雀搜索算法
麻雀搜索算法是一种新型的能够快速收敛、具备强大寻优能力的智能优化算法,由Xue 等[23]于2020 年提出。该算法将麻雀种群分为探索者、跟随者、预警者3类,探索者和跟随者可根据适应度的变化相互转化,但各自在种群中的占比不变。通过寻找食物和反捕预警行为持续更新种群的最佳位置,有n只麻雀的种群为
式中:xnm为麻雀种群X中第n个麻雀在第m个维度的位置信息;
n为麻雀数;
m为变量维度。
麻雀种群的适应度值可表示为
探索者是麻雀种群中拥有较高适应度的成员,负责搜寻食物,其位置更新公式为
式中:t为当前迭代次数;
为在第t次迭代中第i只麻雀的第j维位置;
α∈(0,1],是一个随机数;
itermax为用户设定的最大迭代次数;
R2为种群的预警阈值,R2∈[0,1];
ST为用户设定的安全阈值,ST∈[0.5,1];
Q为随机取值,服从标准正态分布;
L为一个大小为1×m维的矩阵,其元素值都取1。
式(12)中,当R2<ST时,表示种群目前相对安全,探索者在周围环境中可以自由探索觅食;
当R2≥ST时,说明周围有捕食者,预警者发出报警信息,种群飞向安全区域。
为了增加自身的能量值,跟随者会时刻监视探索者,并随时准备抢夺探索者的食物,跟随者的位置更新公式为
式(13)中,当i>n/2 时,表示第i只跟随者仍未获得食物,为了搜寻食物,需更新自身位置,向其他地方探索觅食。通常,预警者占种群数量的10%~20%,其位置更新公式为
式中:λ为随机取值,服从标准正态分布;
为在全局解空间中种群的最佳位置;
k为一个随机数,k∈[-1,1];
ε为较小正则参数,防止分母为0;
fi为种群的适应度;
fw为种群的所有适应度值中的最劣值;
fg为种群的所有适应度值中的最佳值。
式(14)中,当fi>fg时,表示第i只麻雀偏离了群体,容易遭受捕食者的袭击,需更新自身位置以向群体靠拢;
当fi=fg时,群体中心的预警者感知到了危险,为躲避天敌的捕食,它们要向其他群体靠拢。
1.4 改进EMD 端点效应
改进EMD 端点效应的方法有波形延拓法[24]、极值延拓法[25]和数据预测法[26]。波形延拓法如波形匹配延拓法是在原始信号的内部寻找与端点附近处相匹配的波形,将其向外延伸,但依赖内部信号的特征趋势;
极值延拓法利用端点处的极值序列特征直接对极值点进行延拓,如镜像极值延拓法[27]是在端点附近的极值点处放置一面平面镜,延拓的极大值与极小值等于原始序列镜面翻转映射的极大值和极小值,但仍由信号的内部特征尤其是端点处的极值特征确定,无法反映数据的整体特征趋势;
数据预测方法依据特定的数学模型和原始信号的整体内在特征对极值点进行预测,由于预测出的极大值和极小值服从选定模型和数据的整体特征与变化趋势,因此该方法具有较强的稳定性和适应性。本文采用数据预测法,使用LSTM 模型对原始用水量信号两端进行极值延拓,以抑制端点效应,然后将预测的极值点与原始序列合并,再对其进行分解,具体步骤如下:
(1)对原始用水量信号利用“滑动窗口法”分别向两侧进行预测。把n个连续数据输入至LSTM,把与之相邻的数据作为LSTM 的输出,以此训练模型。
(2)使用训练好的LSTM 分别对序列两端进行预测,并在模型的预测输出序列中找出极大值、极小值点(左右两端分别找出1 个极大值和1 个极小值),并与原始序列合并。
(3)使用3 次样条插值法对合并后的用水量序列进行拟合并求均值曲线,之后对其分解,结束分解后截断序列两端合并的极值点数据,从而得到分解结果。
1.5 麻雀算法优化核极限学习机
本研究构建的核极限学习机中有正则化系数C和核参数γ两个参数,利用麻雀搜索算法,以训练误差作为算法的适应度,找出最优的C、γ值,得到SSAKELM 混合用水量预测模型,其步骤如下:
(1)根据人民胜利渠的引黄用水量数据确定KELM 的拓扑结构,以“滑动窗口法”对数据进行划分,并输入到模型中。
(2)初始化模型参数,包括麻雀种群规模、最大迭代次数等,在解空间中对麻雀种群位置随机取值,并计算适应度。
(3)以KELM 的训练误差作为麻雀算法的适应度,依照式(12)~式(14)分别迭代计算各类麻雀的适应度,并确定麻雀的当前最优位置,直至满足条件。
(4)当步骤(3)满足条件循环结束,得到组合模型中最优的C、γ值,随后对用水量进行预测。
1.6 模型构建
本文基于改进的EMD 分解算法结合SSA-KELM,构建了改进的EMD-SSA-KELM 组合用水量预测模型。首先通过LSTM 数据预测法抑制了EMD 算法的端点效应,然后将改进的EMD 分量输入至SSA-KELM中进行预测,最后将分量的预测值累加得到最后的用水量预测值。模型构建流程如图1 所示。

图1 模型构建流程
1.7 模型评估
本文选用相似系数ρi、分解误差ei作为抑制EMD端点效应的评价指标,选用均方根误差(RMSE)、相对误差(RE)和纳什效率系数(NSE)作为构建的混合预测模型效果的评价指标。相似系数用来衡量IMF 分量与原始信号的相关程度,分解误差用来衡量IMF 分量与原始信号的偏差,其计算公式如下:
式中:x为对应原始信号;
imfi为分解后的第i个模态分量;
cov(x)为协方差;
σ(x)为方差;
n为信号个数。
端点效应会导致经验模态分解的分量产生误差,因此抑制端点效应的方法应使得分解误差越小越好,由式(15)、式(16)可知:当ρi越大或ei越小,即相似度越大或分解误差越小时,表示端点效应抑制的效果越好。
RMSE、RE用于衡量预测值同观测值之间的偏差,NSE用于评估模型模拟的好坏,具体计算公式分别为
式中:n为用水量序列长度;
yi为用水量观测值;
为模型模拟值;
为模拟平均值。
人民胜利渠是第一个在黄河下游探索开发的水利工程,本文选用人民胜利渠2010—2019 年以d 为单位的3 497 条引黄用水量观测数据为实验对象,将其以7 ∶3的比例划分成训练集和测试集,以RMSE、NSE为模型评估标准,同SSA-KELM 模型对比,综合评估EMD-SSA-KELM 用水量预测模型的性能。
表1 给出了采用LSTM 预测法、镜像极值延拓法与无极值延拓的分量评价指标,可以看出,LSTM 预测法的相似系数整体相对于镜像极值延拓法和无极值延拓的相似系数较高,分解误差相对较低,说明使用LSTM 预测法对于EMD 端点效应的抑制效果较好。

表1 EMD 分解评估指标对比
EMD 分解和改进的EMD 分解的端点效应控制结果对比见图2(其中:蓝色曲线代表序列无极值延拓、直接对序列进行分解的情况,红色曲线为采用镜像极值延拓的情况,虚线为采用LSTM 预测极值延拓的情况)。结果显示,在IMF3~IMF5 中各分量都存在不同程度的端点效应,但随着分解的进行,在IMF6 中无极值延拓的分量已与经过极值延拓分量的频幅相异,而通过镜像极值延拓和LSTM 预测极值延拓分量的频幅相近,说明端点效应得到了较好的抑制。

图2 IMF 端点效应抑制效果对比
本文以连续5 d 的观测值作为模型的输入,以未来第2、5、7、10 d 的观测值作为输出来训练模型,并在测试集中进行预测。图3 给出了SSA-KELM 和EMDSSA-KELM 的用水量预测结果对比(其中红色、绿色、蓝色曲线分别代表了序列的观测值、SSA-KELM 的预测值、EMD-SSA-KELM 的预测值),结果表明EMDSSA-KELM 相对于SSA-KELM 的拟合效果更好。

图3 不同时间尺度的预测曲线
图4、图5 分别给出了SSA-KELM 和EMD-SSAKELM 对未来第2、5、7、10 d 的用水量预测误差和纳什效率系数结果。图4 中蓝色和红色曲线分别为SSAKELM 和EMD-SSA-KELM 的相对误差曲线,可以看出EMD-SSA-KELM 的相对误差明显低于SSA-KELM 的。图5 中蓝色和红色曲线分别为SSA-KELM 和EMDSSA-KELM 的NSE曲线,可以看出EMD-SSA-KELM模型的可信度更高,可信度趋势更为平稳。
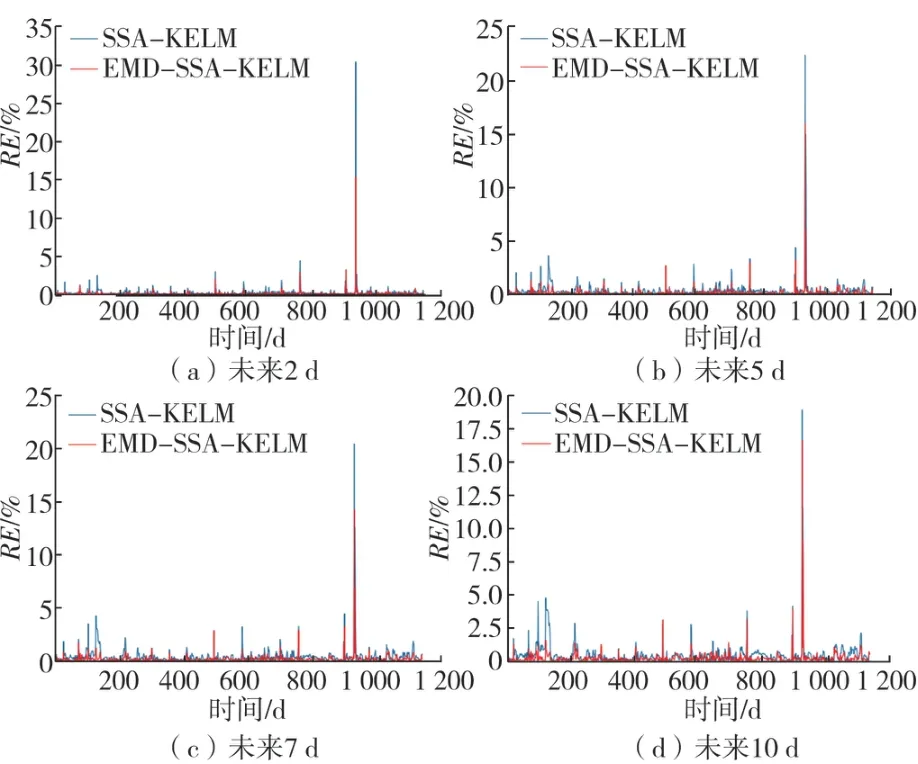
图4 不同时间尺度的误差曲线

图5 不同时间尺度的NSE 评估曲线
综合图4、图5 和表2 的结果显示:EMD-SSAKELM 的均方根误差在每次试验中均相对降低40%以上,SSA-KELM 的纳什系数处于0.28~0.75 的水平,而EMD-SSA-KELM 的纳什系数处于0.75~0.92 的水平,模型可信度明显高于前者,表明EMD-SSA-KELM 相对于SSA-KELM 的预测误差较小,可信度更高,且对于选取不同的数据量,EMD-SSA-KELM 相较于SSAKELM 的稳定性更好,泛化能力更强。

表2 模型预测评估指标对比
本研究将EMD 与SSA-KELM 方法相结合,从多时间尺度对用水量进行辨识,然后根据不同的分量特征变化趋势对用水量进行预测。改善EMD 端点效应,使分量的序列两端信号变化趋势更符合原始特征,可有效抑制分解误差,弥补传统EMD 的不足;
与原始SSA-KELM 模型相比,无论在精度还是可信度上,EMD-SSA-KELM 方法都更优,且更具抗干扰性和泛化能力。然而EMD 分解对用水量时间序列突变点的处理有待优化,分量函数的具体物理意义有待探究,通过分解合成再预测的方式在运行效率上也有待进一步提升。